相关文章

Sklearn K-均值算法
以下是一个使用Sklearn库实现K-均值聚类算法的简单代码示例。K-均值算法是一种迭代算法,用于将数据集分为K个簇,使得每个簇的内部平方误差最小。
# 导入必要的库
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
imp…
编程日记
2025/2/28 2:05:14
Python中的深拷贝与浅拷贝有什么区别?
在Python中,深拷贝和浅拷贝是处理复合对象(例如列表、字典等含有其他对象的对象)时常用到的两种方法。它们之间的主要区别在于复制过程中对内嵌对象的处理方式。 ### 浅拷贝 (Shallow Copy) 浅拷贝创建了一个新对象,其内容是对原始…
编程日记
2025/3/9 5:01:32
Flink广播流 BroadcastStream
文章目录 前言BroadcastStream代码示例Broadcast 使用注意事项 前言
Flink中的广播流(BroadcastStream)是一种特殊的流处理方式,它允许将一个流(通常是一个较小的流)广播到所有的并行任务中,从而实现在不同…
编程日记
2025/3/13 20:23:32
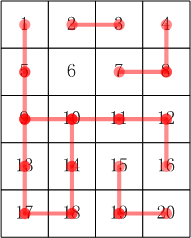
蓝桥杯并查集|路径压缩|合并优化|按秩合并|合根植物(C++)
并查集
并查集是大量的树(单个节点也算是树)经过合并生成一系列家族森林的过程。 可以合并可以查询的集合的一种算法 可以查询哪个元素属于哪个集合 每个集合也就是每棵树都是由根节点确定,也可以理解为每个家族的族长就是根节点。 元素集合…
编程日记
2025/3/6 18:06:51
本地环境下运行Spark程序
1. 前言 终于又有实际的大数据计算业务功能开发了,是对一个以前用SpringBoot来处理Elasticsearch集群上的日志数据的计算程序,这个程序的最大问题就是单进程内存会达到几十G,直到最后运行在中途出现OutOfMemoryError而崩溃掉,毕竟…
编程日记
2025/3/12 6:03:15
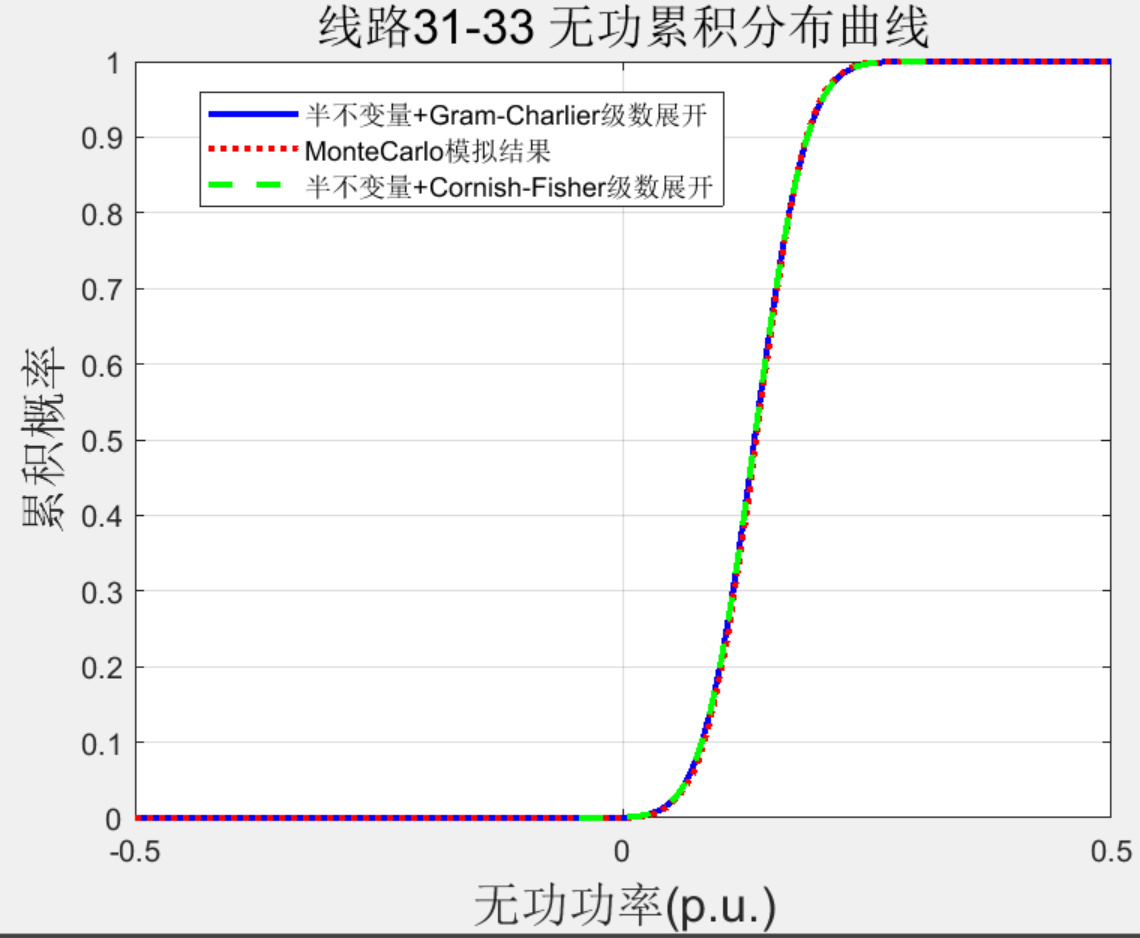
Matlab|【免费】基于半不变量的概率潮流计算
目录 主要内容 部分代码 结果一览
下载链接 主要内容
该程序主要内容是基于半不变量法的概率潮流,包含蒙特卡洛模拟法、半不变量法+Gram-Charlier级数展开以及半不变量法Cornish-Fisher级数展开三种方法以及效果对比,模型考虑了…
编程日记
2025/3/14 3:47:43
docker快速安装和详细安装-保姆教程
docker快速安装和详细安装
一、快速搭建
卸载老版本
yum remove docker docker-common docker-selinux docker-engine安装相关需要的包
yum install -y yum-utils device-mapper-persistent-data lvm2设置docker镜像仓库
yum-config-manager \
--add-repo \
http://mirror…
编程日记
2025/3/10 1:36:09
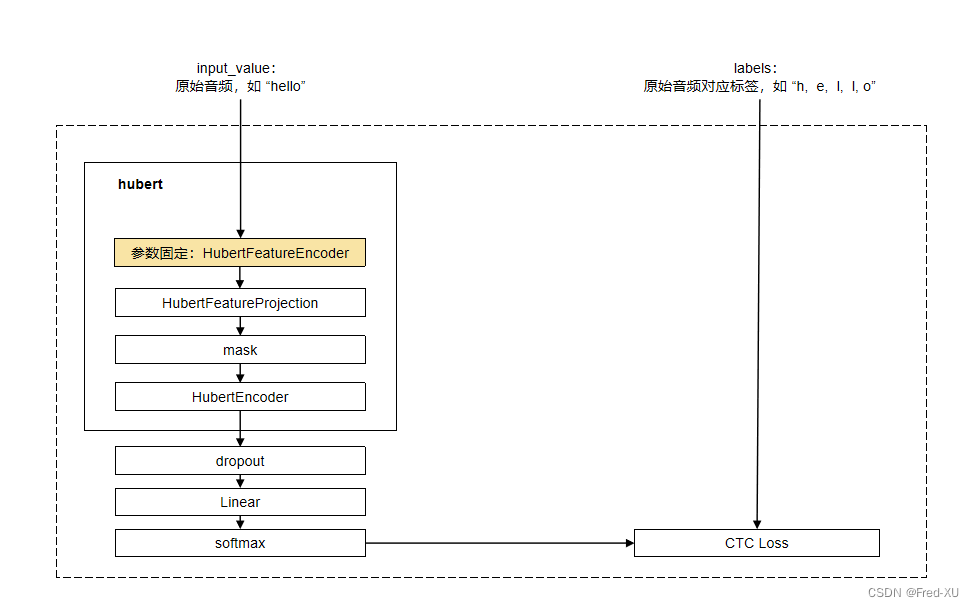
【GPT-SOVITS-06】特征工程-HuBert原理
说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。
知乎专栏地址: 语音生成专栏
系列文章地址: 【GPT-SOVITS-01】源码梳理 【GPT-SOVITS-02】GPT模块解析 【GPT-SOVITS-03】SOVITS 模块-生成模型解析 【G…
编程日记
2025/3/13 6:30:46

