相关文章

论文笔记:Teaching Large Language Models to Self-Debug
ICLR 2024 REVIEWER打分 6666
1 论文介绍
论文提出了一种名为 Self-Debugging 的方法,通过执行生成的代码并基于代码和执行结果生成反馈信息,来引导模型进行调试不同于需要额外训练/微调模型的方法,Self-Debugging 通过代码解释来指导模型识…
编程日记
2025/2/26 4:02:50
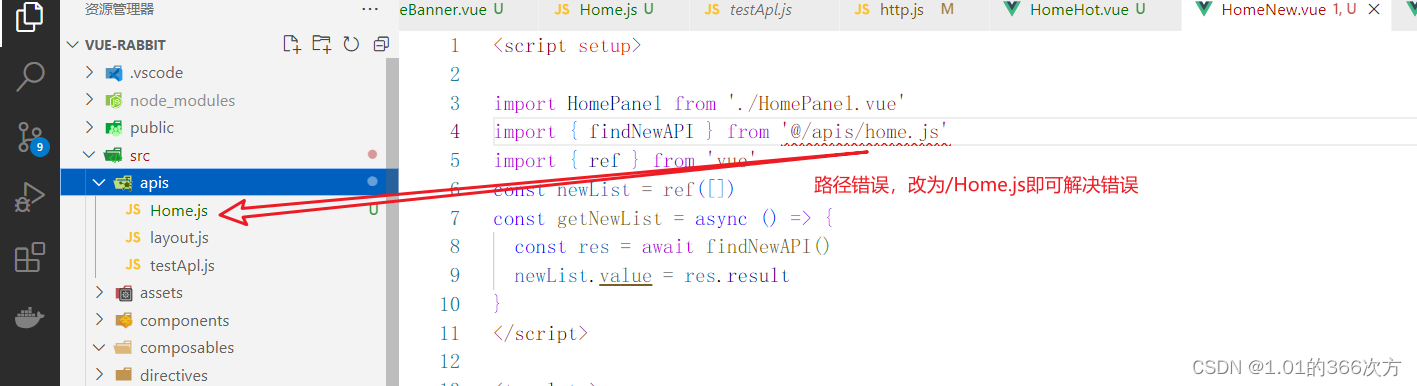
Failed to resolve import “Home/components/HomeNew.vue“. Does the file exist?
错误信息 [plugin:vite:import-analysis] Failed to resolve import "/apis/home.js" from "src/views/Home/components/HomeNew.vue". Does the file exist?
错误原因 路径错误
解决方法
编程日记
2025/2/23 9:34:49

SD-WAN组网,协助企业业务需求灵活调整带宽和网络资源
随着企业网络需求的不断增长和变化,传统的网络架构已经不能满足企业灵活调整带宽和网络资源的需求。而SD-WAN(软件定义广域网)作为一种新型的网络架构,可以帮助企业实现灵活调整带宽和网络资源,满足不同业务需求。本文…
编程日记
2025/2/25 4:01:34

基于Python的高考志愿辅助填报系统
基于Python的高考志愿辅助填报系统是一个利用数据分析和机器学习技术帮助高考生进行志愿填报决策的工具。该系统可以根据考生的分数、兴趣、专业偏好、历史录取数据等因素,为考生提供科学合理的志愿填报建议。以下是设计这样一个系统的步骤和要点。
### 1. 数据收集…
编程日记
2025/2/25 20:25:19
使用node更加方便的操作mysql数据库的小工具
这是一个自己封装的小工具,能够更加方便的操作数据库 地址: 工具首页 git仓库地址 功能还在继续开发当中… 安装
npm install mysqinfo已经引入mysql工具包,无需在项目中再次引入mysql工具包 导入
const db require(mysqinfo)获取数据库对象
// db.dbconnect(mysql地址,mys…
编程日记
2025/2/24 12:11:23
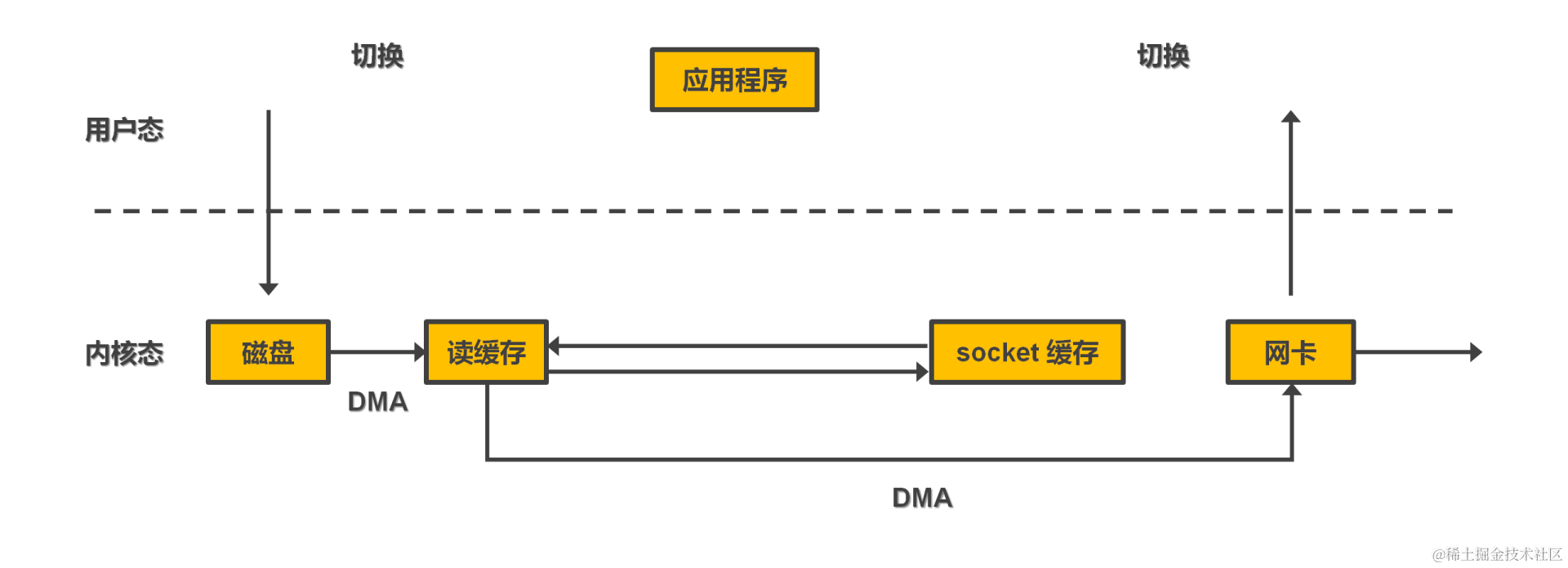
kafka 高吞吐设计分析
说明
本文基于 kafka 2.7 编写。author blog.jellyfishmix.com / JellyfishMIX - githubLICENSE GPL-2.0
概括
支撑 kafka 高吞吐的设计主要有以下几个方面: 网络 nio 主从 reactor 设计模式 顺序写。 零拷贝。
producer
producer 开启压缩后是批量压缩,bro…
编程日记
2025/2/22 4:25:10

