相关文章
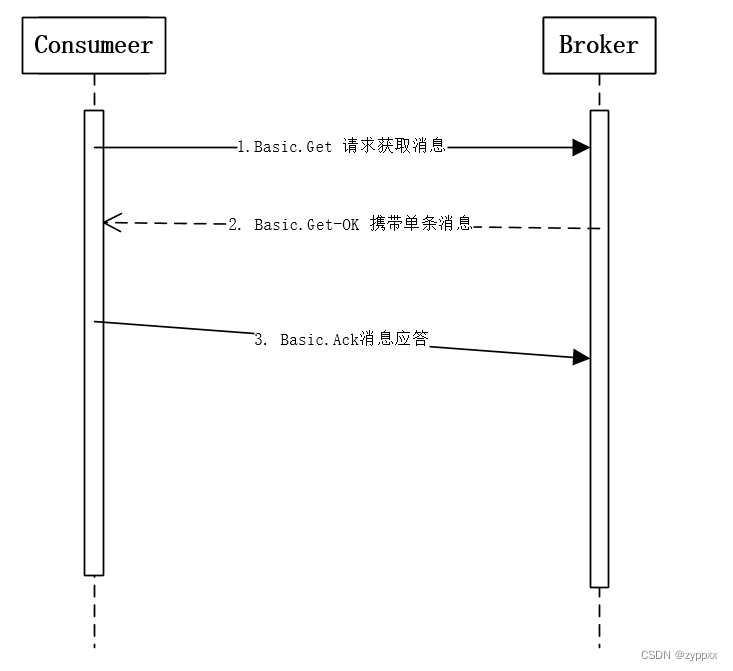
RabbitMQ 消费者
RabbitMQ的消费模式分两种:推模式和拉模式,推模式采用Basic.Consume进行消费,拉模式则是调用Basic.Get进行消费。 消费者通过订阅队列从RabbitMQ中获取消息进行消费,为避免消息丢失可采用消费确认机制 消费者 拉模式拉模式的实…
编程日记
2025/3/11 0:54:07

住宅IP:解锁更快速、稳定的互联网,你准备好了吗?
随着互联网的广泛普及,我们对网络的需求也越来越高。无论是工作、学习还是娱乐,我们都希望能够享受到更快速、稳定的互联网连接。而在实现这一目标的过程中,住宅IP正逐渐崭露头角,成为了一种备受关注的解决方案。那么,…
编程日记
2025/3/10 9:10:59
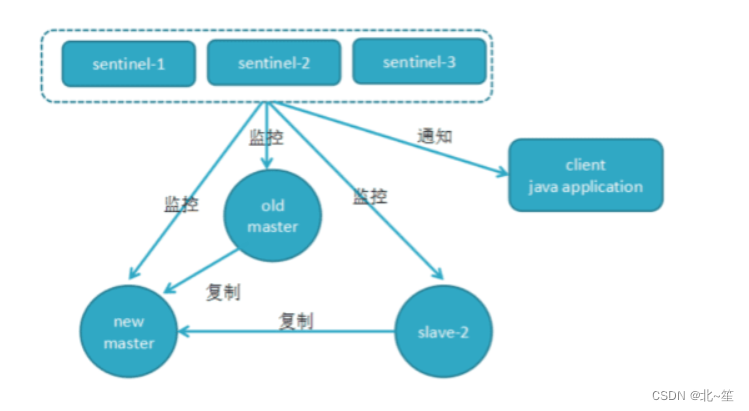
Redis高可用:哨兵机制(Redis Sentinel)详解
目录
1.什么是哨兵机制(Redis Sentinel)
2.哨兵机制基本流程
3.哨兵获取主从服务器信息
4.多个哨兵进行通信
5.主观下线和客观下线
6.哨兵集群的选举
7.新主库的选出
8.故障的转移
9.基于pub/sub机制的客户端事件通知 1.什么是哨兵机制…
编程日记
2025/2/26 8:48:32
Spark大数据分析与实战笔记(第一章 Scala语言基础-1)
文章目录 章节概要1.1 初识Scala1.1.1 Scala的概述1.1.2 Scala的下载安装1.1.3 在IDEA开发工具中下载安装Scala插件1.1.4 开发第一个Scala程序 章节概要 Spark是专为大规模数据处理而设计的快速通用的计算引擎,它是由Scala语言开发实现的,关于大数据技术…
编程日记
2025/3/5 4:24:37
UE学习记录03----UE5.2 使用MVVM示例
1.打开ue5.2新建C项目
2.项目中通过类导向新建C类,父类选择为UMVVMViewModelBase,创建完成会自动打开vs 3.在VS中对新建的类进行宏定义 使用 C 类向导 创建的类声明自动通过 UCLASS() 宏进行处理。 UCLASS() 宏使得引擎意识到这个类的存在,并…
编程日记
2025/3/7 2:58:25
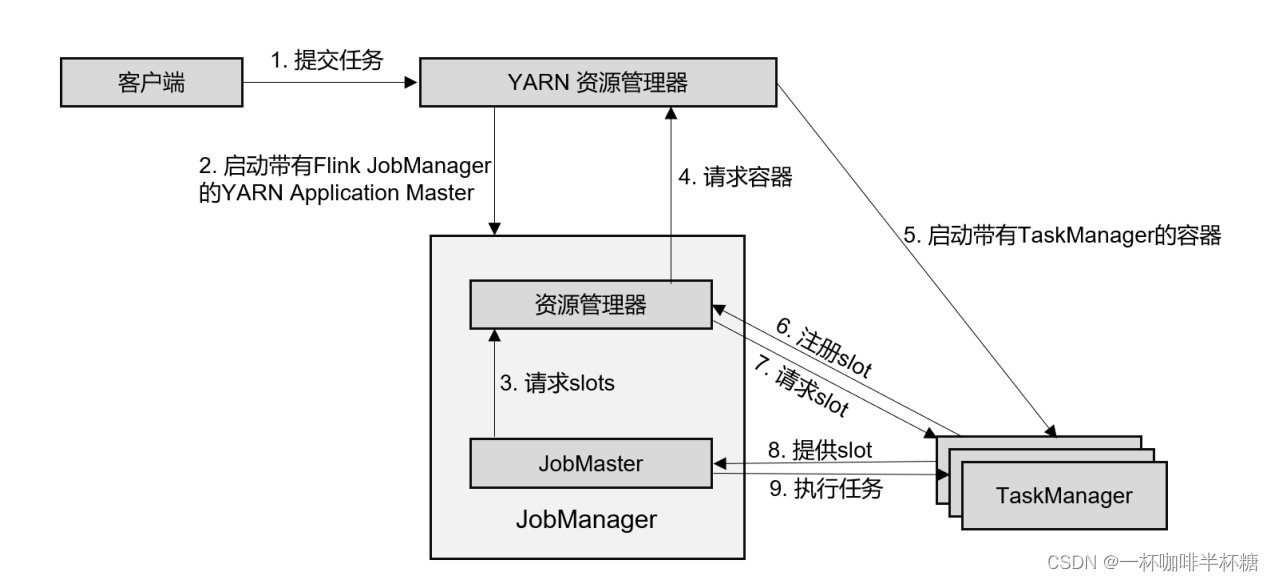
【Flink】Flink提交流程
我们通常在学习的时候需要掌握大数据组件的原理以便更好的掌握这个大数据组件,Flink实际生产开发过程中最常见的就是提交到yarn上进行调度,模式使用的Per-Job模式,下面我们就给大家讲下Flink提交Per-Job任务到yarn上的流程,流程图…
编程日记
2025/3/8 19:24:14

手搓大语言模型 使用jieba分词制作词表,词表大小几十万 加强依赖性
jieba分词词表生成与训练
import numpy as np
import paddle
import pandas as pd
from multiprocessing import Process, Manager, freeze_support
from just_mask_em import JustMaskEm, HeadLoss
from tqdm import tqdm
from glob import glob
import jieba
import warning…
编程日记
2025/2/26 8:47:12
[ubuntu]linux服务器每次重启anaconda环境变量失效
云服务器每次重启后conda不能用了,应该是系统自动把设置环境变量清除了。如果想继续使用,则可以运行一下
minconda3激活方法:
source ~/miniconda3/bin/activate
anaconda3激活方法:
source ~/anaconda3/bin/activate
你也修改bashrc文件去修改环境变量,方法为
vi ~/.b…
编程日记
2025/3/3 22:10:32

