相关文章

Linux(centos7)部署spark
Spark部署模式主要有4种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、Spark On Yarn模式(使用YARN作为集群管理器)和Spark On Mesos模式(使用Mesos作为集…
编程日记
2025/3/12 7:14:59
用选择法对数组中10个整数按由小到大排序
#include <stdio.h>
/** * 主函数:通过用户输入创建一个数组,并将其进行排序后打印。 */ int main(){ // 定义一个排序函数,接受一个整型数组和数组长度作为参数 void sort (int array[],int n); int a[10],i; // 定义一个…
编程日记
2025/3/13 9:02:50
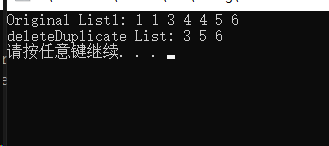
删除有序链表中重复的元素 【C语言】
参考:https://blog.csdn.net/ABABC1234/article/details/131329837
删除有序链表中重复的元素,比如 输入链表1,2,2,3,3,4。输出链表1,4 输入链表1,1,2&#…
编程日记
2025/3/15 8:54:31

【记录】LangChain|Ollama结合LangChain使用的速通版(包含代码以及切换各种模型的方式)
官方教程非常长,我看了很认可,但是看完了之后呢就需要一些整理得当的笔记让我自己能更快地找到需求。所以有了这篇文章。【写给自己看的,里面半句废话的解释都没有,如果看不懂的话直接看官方教程再看我的】
我是不打算一开始就用…
编程日记
2025/3/13 16:15:53
掌握数据相关性新利器:基于R、Python的Copula变量相关性分析及AI大模型应用探索
在工程、水文和金融等各学科的研究中,总是会遇到很多变量,研究这些相互纠缠的变量间的相关关系是各学科的研究的重点。虽然皮尔逊相关、秩相关等相关系数提供了变量间相关关系的粗略结果,但这些系数都存在着无法克服的困难。例如,…
编程日记
2025/3/14 12:30:56
希尔排序算法(Java实现)
1.希尔排序(Shell Sort)
(1)算法思想 先追求表中元素部分有序,再逐渐逼近全局有序。先将待排序表分割成若干形如 L [ i , i d , i 2 d , . . . , i k d ] L[i,id,i2d,...,ikd] L[i,id,i2d,...,ikd]的子表ÿ…
编程日记
2025/3/6 18:10:13

【nc工具信息传输】
nc,全名叫 netcat,它可以用来完成很多的网络功能,譬如端口扫描、建立TCP/UDP连接,数据传输、网络调试等等,因此,它也常被称为网络工具的 瑞士军刀 。
nc [-46DdhklnrStUuvzC] [-i interval] [-p source_po…
编程日记
2025/3/9 17:12:00

