相关文章

强化学习(Reinforcement Learning)与策略梯度(Policy Gradient)
写在前面:本篇博文的内容来自李宏毅机器学习课程与自己的理解,同时还参考了一些其他博客(懒得放链接)。博文的内容主要用于自己学习与记录。
1 强化学习的基本框架 强化学习(Reinforcement Learning, RL)主要由智能体(Agent/Actor)、环境(Environment)、…
编程日记
2025/2/19 6:59:43
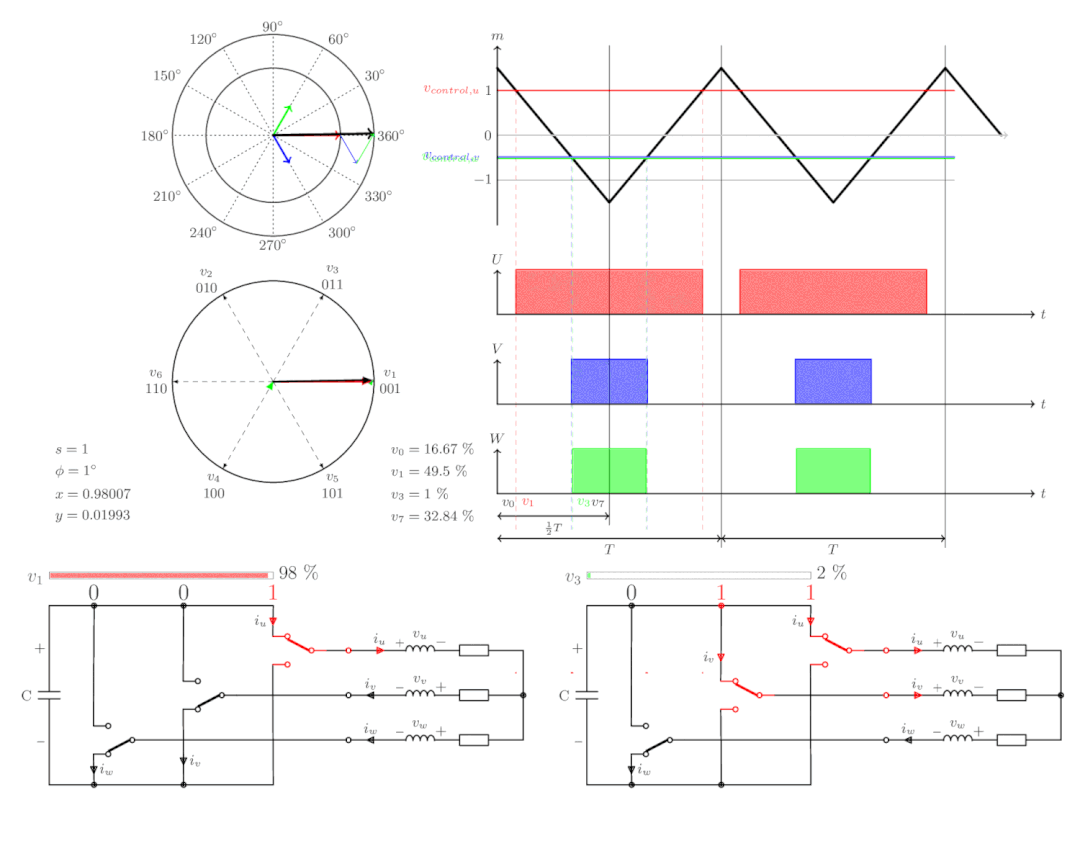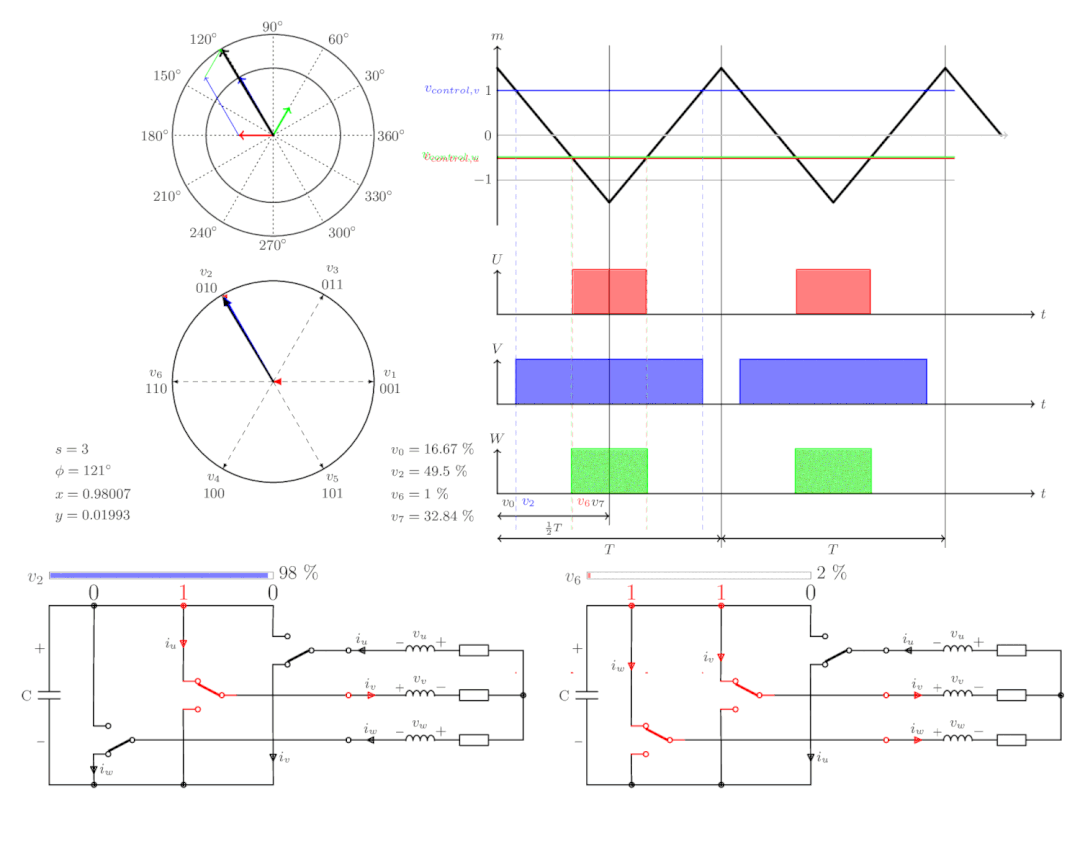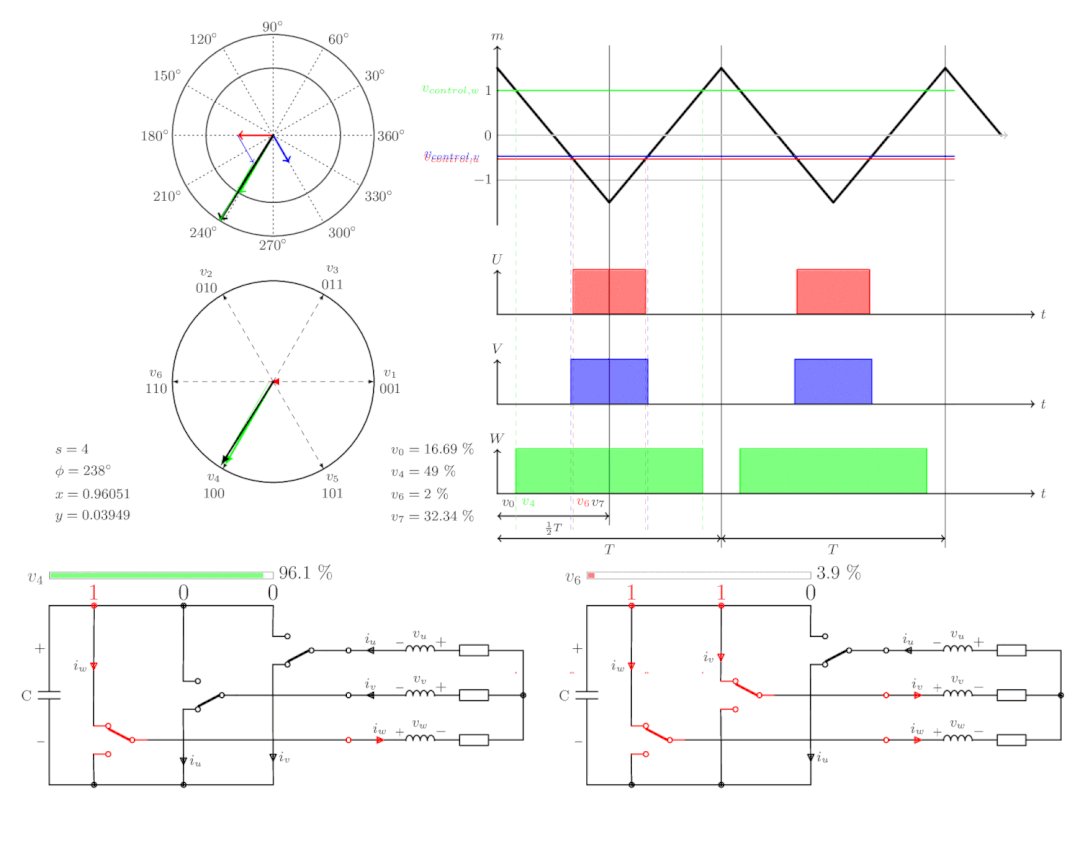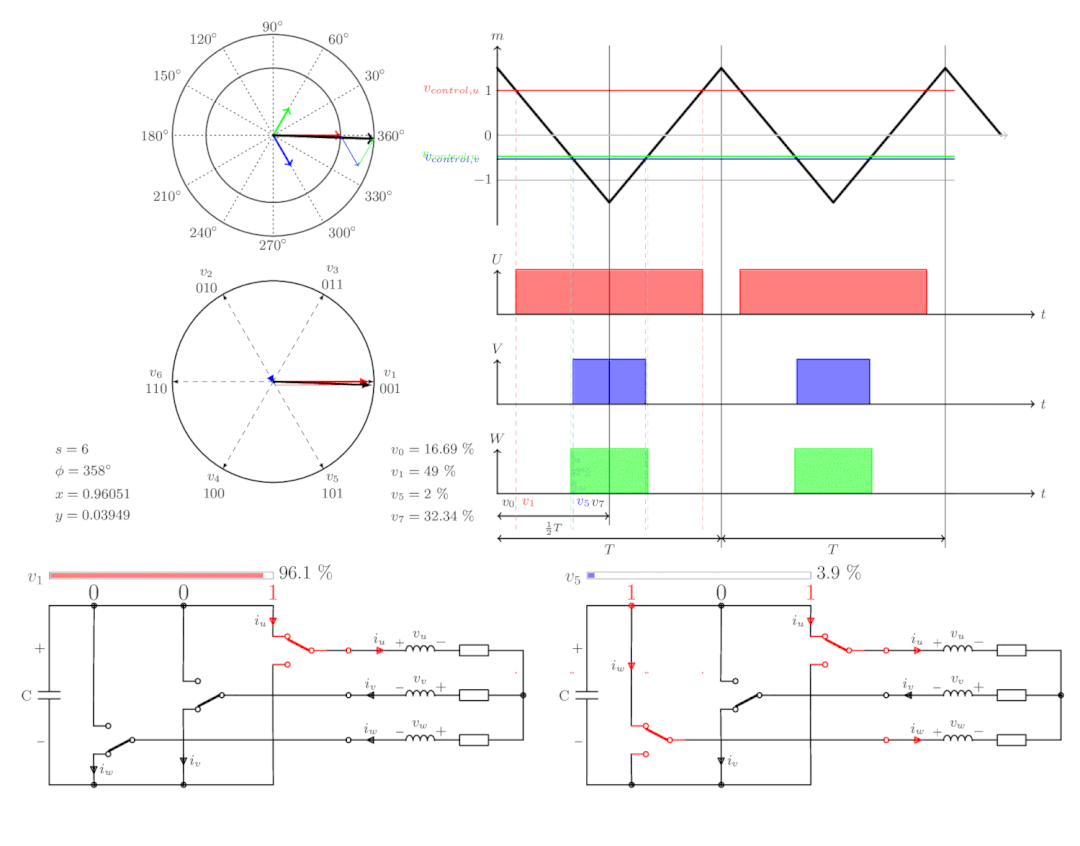
【电机控制】FOC电机控制
FOC(Field-Oriented Control,磁场定向控制)是一种电机控制策略,又称矢量控制,是通过控制变频器输出电压的幅值和频率控制三相直流无刷电机的一种变频驱动控制方法。 FOC 的实质是运用坐标变换将三相静止坐标系下的电机…
编程日记
2025/1/28 15:49:13

保护你的爬虫免受CSRF攻击:深入了解CSRF-Token
CSRF(Cross-Site Request Forgery)是一种常见的网络攻击类型,可用于伪装用户发起的请求,因此保护你的爬虫免受CSRF攻击至关重要。在本文中,我们将深入探讨CSRF-Token,它在CSRF保护中的作用以及爬虫如何处理…
编程日记
2025/2/22 22:17:35
C++项目-数组逆置
将一个数组逆序输出
#include <iostream>
using namespace std;int main() {int arr[] { 2,6,7,32,5,94,5 };int start 0; //起始角标int end sizeof(arr) / sizeof(arr[0]) - 1;//末尾角标(数组长度-1)while(start<end){int te…
编程日记
2025/2/20 5:48:58

LiveMedia视频中间件视频隐私打码直播解决方案
一、方案背景 随着科技的发展,视频监控系统已经成为了我们生活中不可或缺的一部分。无论是在公共区域,还是在私人场所,我们都可以看到各种各样的监控设备。这些设备的出现,无疑提高了我们的生活安全,使得我们可以更好地…
编程日记
2025/2/19 13:09:53

线性代数 --- 矩阵的QR分解,A=QR
矩阵的QR分解,格拉姆施密特过程的矩阵表示 首先先简单的回顾一下Gram-Schmidt正交化过程的核心思想,如何把一组线性无关的向量构造成一组标准正交向量,即,如何把矩阵A变成矩阵Q的过程。 给定一组线性无关的向量a,b,c,我…
编程日记
2025/2/25 3:05:11
window系统进行goolge代理配置(falcon proxy+burpsuite)
linux系统自带burpsuite抓包软件,只要火狐下个代理扩展就可以抓包了,想着每次抓包还得去虚拟机抓就有点小烦躁,所以想着给自己本机也弄个burpsuite,有想法就开整!
一、goole代理扩展插件falcon proxy
1、由于goole应…
编程日记
2025/2/24 3:20:25

